1일 1커밋🌱
CPU 스케줄링
1. CPU 스케줄링 개요
프로그램을 실행시키면 메모리에 프로세스가 생성되고, 각 프로세스에는 한 개 이상의 쓰레드가 있다. 프로세스들은 CPU를 차지하기 위해 운영체제의 명령을 기다리고 있다. 운영체제는 모든 프로세스에게 CPU를 할당, 해제하는데 이를 CPU 스케줄링이라고 한다.
CPU 스케줄링에서 OS, 스케줄러가 고려해야 할 사항은 두 가지가 있다.
- 어떤 프로세스에게 CPU 리소스를 줘야 하는가?
- CPU를 할당받은 프로세스가 얼마의 시간 동안 CPU를 사용해야 하는가?
이 두 가지 고려 사항이 컴퓨터의 성능에 굉장히 큰 영향을 미치게 된다.
CPU를 할당받아 실행하는 작업을 CPU Burst라고 부르고, 입출력 작업을 I/O Burst라고 부른다.
2. 다중큐
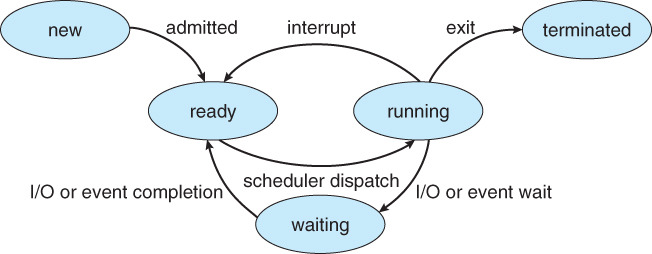
프로세스가 대기하고 있는 준비상태와 대기상태는 큐 자료구조로 관리된다.
프로세스가 실행상태에서 준비상태로 돌아갈 때, 운영체제는 해당 프로세스의 우선순위를 보고 그에 맞는 준비 큐에 넣는다.
CPU 스케줄러는 준비 상태의 다중 큐에 들어있는 프로세스들 중에 적당한 프로세스를 선택해서 실행 상태로 전환시킨다.
프로세스가 실행상태에서 대기상태로 오게되면, I/O 작업 종류에 따라 분류된 큐에 들어간다.
예를 들면 하드디스크 작업은 HDD 큐에 들어가고 하드디스크 작업이 완료되어 인터럽트가 발생되면 HDD 큐를 뒤져서 다시 꺼내간다.
또한 실제로는 큐에 프로세스가 들어가는 것이 아니라 프로세스의 정보를 가지고 있는 PCB가 들어간다.
정리하면, 프로세스의 정보를 담고 있는 PCB는 준비 상태의 다중 큐에 들어가서 실행되기를 기다리고 있고 CPU 스케줄러에 의해 실행 상태로 전환된다. 이때 CPU 스케줄러는 준비 상태의 다중 큐를 참조해서 어떤 프로세스를 실행시킬지 결정한다. I/O 작업도 비슷하다. 실행 중인 프로세스에서 I/O 작업이 발생하면 해당 I/O 작업의 종류별로 나뉜 큐에 들어가고, CPU 스케줄러는 이를 참조해 스케줄링을 한다.
3. 스케줄링 목표
스케줄링의 목표는 다음과 같다.
첫번째는 리소스 사용률이다. CPU 사용률을 높이는 것을 목표로 할 수도 있고, I/O 디바이스의 사용률을 높이는 것을 목표로 할 수도 있다.
두번째는 오버헤드의 최소화이다. 스케줄링을 하기 위한 계산이 너무 복잡하거나 컨텍스트 스위칭을 너무 자주하면 오버헤드가 커지게 된다.
세번째는 공평성이다. 대부분의 운영체제에서는 모든 프로세스에게 공평하게 CPU가 할당되어야 한다.
네번째는 처리량이다. 같은 시간 내에 더 많은 처리를 할 수 있는 방법을 목표로 한다.
다섯번째는 대기 시간이다. 작업을 요청하고 실제 작업이 이루어지기 전까지 대기 시간이 짧은 것을 목표로 한다.
여섯번째는 응답 시간이다. 대화형 시스템에서 사용자의 요청에 얼마나 빠르게 반응하는지가 중요하기 때문에 응답 시간이 짧은 것을 목표로 한다.
위의 목표들을 모두 최고의 수준으로 유지하기는 힘들다. 왜냐하면 목표 간에 서로 상충되는 상황에 있기 때문이다.
예를 들어 처리량을 높이기 위해서는 하나의 프로세스에 CPU를 오래 할당해야 한다. 반면 응답 시간을 줄이기 위해서는 여러 프로세스에 골고루 CPU를 할당해야 하는데 서로 상반되기 때문에 처리량과 응답 시간의 목표를 같이 달성할 수 없다.
이때는 사용자가 사용하는 시스템에 따라서 목표를 다르게 설정한다. 터치 스크린과 같이 사용자에게 빠른 응답이 필요한 경우는 응답 시간이 짧도록 초점을 맞추고, 과학 계산 같은 경우는 처리량이 높도록 초점을 맞춘다. 일반 사용자의 경우 특별한 목적이 없다면 어느 한쪽에 치우치지 않도록 밸런스를 유지하는 것이 중요하다.
4. 스케줄링 알고리즘(1) - FIFO(First In, First Out)
FIFO는 First In, First Out의 약자이다. 먼저 들어온 작업이 먼저 나간다는 뜻으로, 스케줄링 큐에 들어온 순서대로 CPU를 할당받는 방식이다.
- 장점 : 단순하고 직관적이다.
- 단점 :
- 한 프로세스가 완전히 끝나야 다음 프로세스가 실행되기 때문에, 실행 시간이 짧고 늦게 도착한 프로세스가 실행 시간이 길고 빨리 도착한 프로세스의 작업을 기다려야 한다.
- I/O 작업이 있다고 한다면, CPU는 I/O 작업이 끝날 때까지 쉬고 있기 때문에 CPU 사용률이 떨어지게 된다.
스케줄링의 성능은 평균 대기 시간으로 평가하게 되는데, 평균 대기 시간은 프로세스 여러 개가 실행될 때 이 프로세스들 모두가 실행되기까지 대기 시간의 평균을 말한다.
FIFO 알고리즘을 사용하면 Burst Time이 짧은 프로세스가 먼저 실행될 수록 평균 대기 시간이 짧다. 즉 작업의 순서에 따라 평균 대기 시간이 크게 달라진다.
FIFO 알고리즘은 프로세스의 Burst Time에 따라 성능의 차이가 심하게 나기 때문에 현대 운영체제에서 잘 쓰이지 않고 일괄 처리 시스템에 쓰인다.
5. 스케줄링 알고리즘(2) - SJF(Shortest Job First)
FIFO 알고리즘의 경우 작업의 순서에 따라 평균 대기 시간이 크게 달라질 수 있다. 운영체제를 연구하는 사람들은 여기서 아이디어를 얻어 Burst Time이 짧은 프로세스를 먼저 실행하는 알고리즘을 만들고 Shortest Job First라는 이름을 붙였다. Short Job First 알고리즘은 이론적으로 FIFO보다 성능이 더 좋다.
하지만 실제로 구현을 하려고 하니 문제가 발생했다. 문제는 크게 두가지가 있다.
첫번째 문제는 어떤 프로세스가 얼마나 실행될지 예측하기 힘들다는 것이다. 인터넷 브라우저를 실행시키고 뮤직 플레이어를 실행시켰다고 가정해보면, 노래를 틀어놓고 브라우저에서 날시만 확인하고 브라우저는 바로 종료할 수도 있고, 인터넷 쇼핑을 하느라 계속 켜놓을 수도 있다. 이처럼 프로세스의 종료 시간은 예측하기가 거의 불가능에 가깝다.
두번째 문제는 Burst Time이 긴 프로세스는 아주 오랫동안 실행되지 않을 수도 있다는 것이다. Short Job First는 Burst Time이 짧은 프로세스가 먼저 실행되기 때문에 Burst Time이 긴 프로세스는 뒤로 밀려난다. 만약 Burst Time이 짧은 프로세스가 중간에 계속 들어오면 Burst Time이 긴 프로세스는 앞에 모든 프로세스가 종료되기까지 기다려야 하기 때문에 공평하지 않다.
이러한 문제 때문에 Shortest Job First 알고리즘은 사용되지 않는다.
6. 스케줄링 알고리즘(3) - RR(Round Robin)
FIFO 알고리즘의 경우 일괄 처리 시스템에 적합해서 시분할 처리 시스템에서는 사용하기 힘들고, Shortest Job First 알고리즘은 프로세스의 종료 시간을 예측하기 힘들다는 문제점이 있다. 따라서 운영체제를 연구하는 사람들은 가장 단순한 FIFO 알고리즘에서 단점을 해결해 보기로 했다.
FIFO 알고리즘의 단점은 먼저 들어온 프로세스가 전부 끝나야 다음 프로세스가 실행되는 것이다.
이 문제를 해결하기 위해서 한 프로세스에게 일정 시간만큼 CPU를 할당하고, 할당 시간이 지나면 강제로 다른 프로세스에게 일정 시간만큼 CPU를 할당한다. 강제로 CPU를 뺏긴 프로세스는 큐의 가장 뒷부분으로 밀려난다. 이 알고리즘을 라운드 로빈이라고 부른다.
프로세스에게 할당하는 일정 시간은 타임 슬라이스 혹은 타임 퀸텀이라고 브란다.
그러나 평균 대기 시간이 비슷하다면 라운드 로빈 알고리즘이 FIFO 알고리즘에 비해 더 비효율적인 방식이다. 라운드 로빈 알고리즘은 컨텍스트 스위칭이 있기 때문에 컨텍스트 스위칭 시간이 더 추가되기 때문이다. 라운드 로빈 알고리즘의 성능은 타임 슬라이스 값에 따라 크게 달라진다.
먼저 타임 슬라이스가 무한대라고 가정하면 먼저 들어온 프로세스의 작업이 종료될 때까지 실행하니 FIFO 알고리즘이 돼버린다.
타임 슬라이스가 5초라고 가정하면 웹 브라우저와 뮤직 플레이어를 실행시키면 웹 브라우저가 5초 동안 동작하다가 멈추고, 음악이 5초 재생되다가 멈추고, 다시 웹 브라우저가 5초 동작하기 굉장히 끊기게 된다.
타임 슬라이스를 1밀리초로 아주 작은 값으로 설정하면 웹 브라우저와 뮤직 플레이어가 동시에 동작하는 것처럼 느끼게 될 것이다.
하지만 타임 슬라이스를 너무 작게 설정하면 컨텍스트 스위칭이 너무 자주 일어나게 되고 타임 슬라이스에서 실행되는 프로세스의 처리량보다 컨텍스트 스위칭을 처리하는 양이 훨씬 커져서 오버헤드가 너무 커지게 된다.
최적의 타임 슬라이스를 결정하는 방법은 사용자가 느끼기에 여러 프로세스가 버벅이지 않고 동시에 실행되는 것처럼 느껴지면서 오버헤드가 너무 크지 않은 값을 찾아야 하는 것이다.
실제로 윈도우의 경우에 타임 슬라이스가 20ms, 유닉스는 100ms 정도로 굉장히 짧다.
7. 스케줄링 알고리즘(4) - MLFQ(Multi Level FeedBack Queue)
MLFQ는 오늘날 운영체제에서 가장 일반적으로 쓰이는 CPU 스케줄링 기법이다. 먼저 어떻게 MLFQ가 탄생했는지 알아보자. MLFQ는 Round Robin의 업그레이드된 알고리즘이기 때문에 라운드 로빈 알고리즘의 예로 알아보자.
프로세스 2개가 있다고 가정하자. 첫번째 프로세스는 P1이고 두번째 프로세스는 P2이다. P1은 I/O 작업 없이 CPU 연산만 하는 프로세스이다. P2는 1초 CPU 연산을 하고 10초 동안 I/O 작업을 한다. 여기서 P1은 대부분의 시간을 CPU 연산을 하기 때문에 CPU Bound Process라 하고, 반면 P2는 대부분의 시간을 I/O로 보내고 CPU 연산은 조금만 하기 때문에 I/O Bound Process라고 한다. CPU Bound Process가 가장 중요하게 생각하는건 CPU 사용률과 처리량이다. 반면 I/O Bound Process가 가장 중요하게 생각하는 건 응답속도이다. 이 프로세스 2개를 가지고 두 가지 상황에서 실행시켜보자.
첫번째 상황은 타임 슬라이스가 100초인 경우이다. P2가 먼저 실행된다고 가정해보면 P2는 1초 실행되고 I/O 작업을 요청하고 기다린다. 이때 P1이 실행되는데 타임 슬라이스 크기인 100초만큼 실행된다. P1이 실행되는 도중에 10초가 지났을 때 P2가 요청한 I/O 작업이 완료되고 인터럽트가 발생한다. 그럼 P2는 다시 큐에 들어가 CPU를 할당받을 준비가 된다. P1은 100초 실행하면 CPU를 뺏기고 큐에 있던 P2는 다시 1초 실행되고 I/O 작업을 요청하고 다시 기다린다. 이 과정이 모든 작업이 완료될 때까지 계속 반복된다.
두번째 상황은 타임 슬라이스가 1초인 경우이다. P2가 1초 실행되고 I/O 작업을 요청하고 기다린다. 이때 P1이 실행되는데 타임 슬라이스 크기인 1초만큼 실행된다. 지금 P2는 I/O 작업이 끝나지 않아 계속 기다리는 상황이다. 그렇기 때문에 P1은 종료되고 바로 큐에 들어가는데 큐가 비어있기 때문에 P1이 다시 바로 실행된다. 이렇게 P1이 10번, 즉 10초 동안 실행되면 P2는 I/O 작업이 끝나 인터럽트가 발생되고 P2는 큐에 들어간다. 그럼 P2는 다시 1초 실행되고 다시 I/O 작업을 기다린다. 이 과정이 모든 작업이 완료될 때까지 계속 반복된다.
위의 두 가지 상황을 비교해보면 CPU 사용률을 보면 CPU는 쉬지 않고 일하기 때문에 CPU 사용률이 100%이다. 하지만 I/O 사용률을 보면 P1이 실행되는 동안 P2의 I/O 작업이 완료된 시점부터 기다리는 상황이 발생하기 때문에 10/101으로 대략 10% 정도밖에 되지 않는다.
두번째 상황도 CPU 사용률을 보면 CPU는 쉬지 않고 일하기 때문에 CPU 사용률이 100%이다. 그러나 첫번째 상황과 달리 P1의 타임 슬라이스가 작기 때문에 P2가 기다리며 낭비되는 시간이 거의 없고 10/11로 대략 90% 정도 나오게 된다.
즉, CPU 사용률과 I/O 사용률 전체를 생각하면 타임 슬라이스가 작은 값이 더 좋다는 결론이 나온다. 그러나 타임 슬라이스가 100초에서 1초로 작아질 때 P1과 P2의 입장에서 보면 한쪽은 손해를 보고 한쪽은 이득을 보는 구조이다. CPU Bound Process인 P1은 100초였던 실행시간이 1초로 줄었지만, 연속으로 실행되기 때문에 손해가 없는 것처럼 보인다. 하지만 컨텍스트 스위칭을 하기 때문에 오버헤드가 생겨서 손해를 본다. 반면 I/O Bound Process인 P2는 I/O 사용률이 굉장히 높아졌기 때문에 이득을 보게 된다.
운영체제를 연구하는 사람들은 손해보는 프로세스가 어떻게 하면 손해를 보지 않을지 고민을 하게 되고 바로 여기서 Multi Level FeedBack Queue가 탄생하게 된다.
MLFQ는 기본적으로는 CPU 사용률과 I/O 사용률이 좋게 나오는 작은 크기의 타임 슬라이스를 선택한다. 그리고 P1과 같은 CPU Bound Process에게는 타임 슬라이스를 크게 주는 것이다.
운영체제 입장에서는 CPU Bound Process와 I/O Bound Process를 어떻게 구분할까? CPU를 사용하는 프로세스가 실행하다가 스스로 CPU를 반납하면 CPU 사용이 적은거니 I/O Bound Process일 확률이 높다. 반대로 CPU를 사용하는 프로세스가 타임 슬라이스 크기를 오버해서 CPU 스케줄러에 의해 강제로 CPU를 뺏기는 상황이면 CPU 사용이 많은 것이니 CPU Bound Process일 확률이 높다.
이런 아이디어를 통해 우선순위를 가진 큐를 여러 개 준비해둔다. 우선순위가 높으면 타임 슬라이스가 작고, 우선순위가 낮을수록 타임 슬라이스 크기가 커진다. 만약 P1처럼 타임 슬라이스 크기를 오버해서 강제로 CPU를 뺏긴다면 P1은 원래 있던 큐보다 우선순위가 더 낮은 큐로 이동하게 된다. 그리고 다음번에 실행될 때는 타임 슬라이스 크기가 조금 더 커지게 되고, 여기서도 부족하면 다음엔 더 큰 타임 슬라이스를 할당받게 된다. 최종적으로는 타임 슬라이스가 무한 초에 가깝게 할당되기 때문에 FIFO처럼 연속적으로 작업을 마칠 수 있게 된다.
참고
댓글남기기