1일 1커밋🌱
메모리
1. 메모리 종류
컴퓨터에는 여러 종류의 메모리가 있다. 왜 컴퓨터에는 여러 종류의 메모리가 필요하며 서로 무엇이 다른지 알아보자.
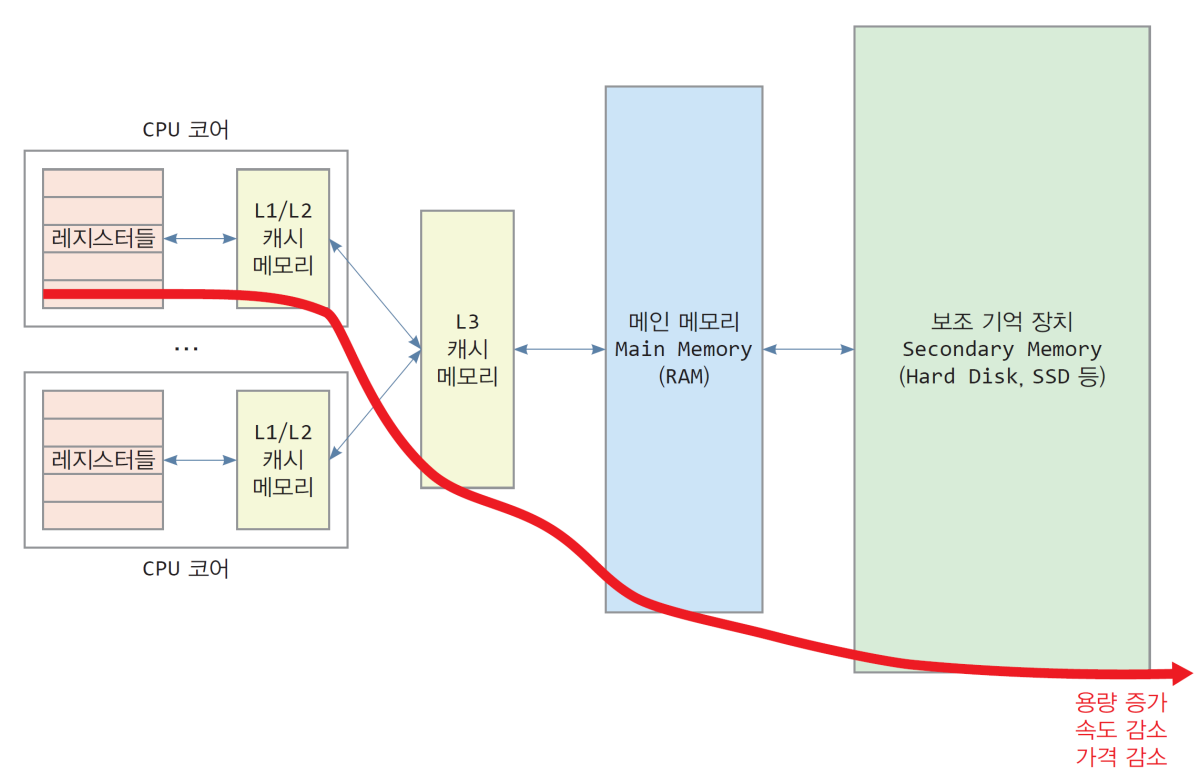
컴퓨터에서 사용되는 메모리들이다. 오른쪽으로 갈수록 가격은 싸지고 용량은 커지만 속도는 느려진다.
레지스터
- 레지스터는 가장 빠른 기억 장소로 CPU 내에 존재한다.
- 컴퓨터의 전원이 꺼지면 데이터가 사라지기 때문에 휘발성 메모리라고 부른다.
- CPU를 구분할 때 32비트와 64비트로 구분하고는 하는데, 여기서 32비트와 64비트는 레지스터의 크기를 말한다. 32비트의 레지스터를 가지고 있으면 32비트 CPU라고 말하고, 64비트의 레지스터를 가지고 있으면 64비트 CPU라고 부른다.
- CPU는 계산을 할 때 메인 메모리에 있는 값을 레지스터로 가져와서 계산을 한다. 계산 결과는 다시 메인 메모리에 저장시킨다.
캐시
- 레지스터와 메인 메모리 사이에는 캐시라는 휘발성 메모리가 있다.
- 레지스터는 CPU가 사용하는 메모리로 매우 빠르다. 그에 반해 메인 메모리는 너무 느리기 때문에 메인 메모리에 있는 값을 레지스터로 옮기려면 한참 걸리기 때문에 필요한 것 같은 데이터를 미리 가져오기로 한다. 미리 가져온 데이터를 저장하는 곳이 바로 캐시이다.
- 캐시는 성능의 이유로 여러 개를 둔다. 만약 CPU가 값을 요청해 레지스터로 값을 옮겨야 한다면 단계에 따라 가장 속도가 빠른 L1 캐시를 보고, 여기에 없다면 L2 캐시, L3 캐시를 확인해보고 여기도 없다면 메인 메모리에서 값을 가져온다.
메인 메모리
- 메인 메모리는 실제 운영체제와 다른 프로세스들이 올라가는 공간이다.
- 전원이 공급되지 않으면 데이터가 지워지기 때문에 휘발성 메모리이다.
- 하드디스크나 SSD보다 속도는 빠르지만 가격이 비싸기 때문에 데이터를 저장하기보다는 실행 중인 프로그램만 올린다.
보조 기억 장치(SSD, 하드디스크)
- 컴퓨터에는 사무용 프로그램이나 게임, 작업한 파일을 저장할 필요가 있는데 이전에 살펴본 메모리들은 휘발성 메모리이고 가격이 비싸기 때문에 저장하기 어렵다. 그래서 가격이 저렴하고 전원이 공급되지 않아도 데이터가 지워지지 않는 비휘발성 메모리를 만들었다.
현재 우리는 레지스터와 캐시, 메인 메모리, 하드디스크로 가격과 속도를 절충해주는 구조 덕분에 저렴하고 빠른 컴퓨터를 이용할 수 있다.
2. 메모리와 주소
오늘날 컴퓨터는 폰 노이만 구조로 되어 있고, 폰 노이만 구조는 모든 프로그램을 메모리에 올려서 실행시킨다.
유닛 프로그래밍 환경에서는 하나의 프로그램만 메모리에 올라오기 때문에 메모리 관리가 어렵지 않았으나 멀티 프로그래밍 환경에서는 여러 프로세스가 올라오니 복잡하고 어려워졌다.
운영체제는 메모리를 관리하기 위해서 1바이트 크기로 구역을 나누고 숫자를 매긴다. 이 숫자는 주소라고 부른다.
32비트 CPU는 레지스터 크기가 32비트이고, CPU가 처리하는 ALU도, 데이터가 이동하는 버스도 32비트이다. 또한 CPU가 다룰 수 있는 메모리도 2^32로 4GB이다.
64비트 CPU는 레지스터 크기와 ALU, 버스의 크기도 64비트이다. 다룰 수 있는 메모리 크기는 2^64로 거의 무한대에 가깝다. 64비트 CPU가 32비트 CPU보다 한 번에 처리할 수 있는 양이 많기 때문에 속도가 더 빠르다.
메모리를 컴퓨터에 연결하면 0x0번지부터 시작하는 주소 공간이 있는데, 이를 물리 주소 공간이라고 한다. 이와 다르게 사용자 관점에서 바라본 주소 공간은 논리 주소 공간이라고 부른다. 사용자는 물리 주소를 몰라도 논리 주소로 물리 주소에 접근할 수 있다.
메모리에는 운영체제와 수많은 프로세스가 올라온다. 그중에 운영체제는 특별하기 때문에 운영체제를 위한 공간을 따로 만들어둔다. 만약 사용자가 악의적인 공간을 만들어 사용자가 프로세스가 운영체제를 침범하면 굉장히 위험할 수도 있다. 그래서 하드웨어적으로 운영체제 공간과 사용자 공간을 나누는 경계 레지스터를 만들었다. 경계 레지스터는 CPU 내에 존재하는 레지스터로, 메모리 관리자가 사용자 프로세스가 경계 레지스터의 값을 벗어났는지 검사하고, 만약 벗어났다면 그 프로세스를 종료시킨다.
메모리에는 절대 주소와 상대 주소라는 개념이 있다. 개발자는 프로그램을 만들 때 프로그램이 실행될 주소를 신경쓰지 않고 개발을 한다. 그 이유는 컴파일러가 컴파일을 할 때 메모리 0x0번지에서 실행한다고 가정하기 때문이다. 개발자의 프로그램을 실행시켜 사용자 공간 0x4000번지에 올라왔다고 가정해보자. 컴파일러는 0x0번지라고 가정해서 프로그램을 만들었고 이는 상대 주소이다. 실제 프로그램이 올라간 주소는 0x4000번지 인데 이는 메모리 관리자가 바라본 절대 주소이다. 사용자가 바라본 주소인 상대 주소는 논리 주소 공간이라 부르고, 메모리 관리자가 바라본 주소는 절대 주소는 물리 주소 공간이라고 부른다.
예시로 사용자가 0x100번지에 있는 데이터를 요청한다고 가정하자. CPU는 메모리 관리자에게 0x100번지에 있는 데이터를 가져오라고 한다. 메모리 관리자는 CPU가 요청한 0x100번지와 재배치 레지스터에 있는 0x4000번지의 값을 더한 0x4100번지에 접근해서 데이터를 가져온다. 재배치 레지스터에는 프로그램의 시작 주소가 저장되어 있다.
메모리 관리자는 사용자가 메모리에 접근할 때마다 이렇게 계산한다. 메모리 관리자 덕분에 모든 사용자 프로세스는 0x번지부터 시작한다는 가정으로 편하게 프로그램을 만들 수 있고 만약 시작 영역이 바뀌더라도 재배치 레지스터만 변경해주면 되기 때문에 굉장히 유연하다.
3. 메모리 할당방식
예전 유닛 프로그래밍 환경에서 메모리보다 더 큰 프로그램을 실행시키는 방법은 무엇이었을까? 방법은 간단하다.
큰 프로그램을 메모리에 올릴 수 있도록 잘라서 당장 실행시켜야 할 부분만 메모리에 올리고 나머지는 용량이 큰 하드디스크에 저장하는 기법이다. 이 기법을 메모리 오버레이라고 한다.
큰 프로그램을 작게 나누어 일부만 실행하고 일부는 하드디스크에 저장된다고 했는데, 정확히는 하드디스크의 스왑 영역이라는 곳에 저장된다.
만약 메모리에 1GB를 올리고 스왑 영역에 8GB를 올려서 실행한다고 하면 사용자는 메모리가 9GB인 것처럼 느끼게 된다. 하지만 스왑과정이 있기 때문에 실제 메모리가 9GB인 컴퓨터보다는 느리게 동작한다.
스왑 : 스왑영역에 있는 데이터 일부를 메모리로 가져오고 메모리에 있는 데이터를 스왑영역으로 옮기는 것
그럼 오늘날과 같이 메모리에 여러 프로세스가 올라오는 멀티 프로그랭 환경에서는 메모리 관리를 어떻게 할까? 운엥체제를 연구하는 사람들은 메모리를 어떤 크기로 나눌까 고민을 했고, 두 가지 방식으로 나눈다.
- 첫번째는 가변 분할 방식이다. 가변 분할 방식은 프로세스의 크기에 따라 메모리를 나누는 방식이다.
- 두번째는 고정 분할 방식으로 프로세스의 크기와는 상관없이 메모리를 정해진 크기로 나누는 방식이다.
가변 분할 방식과 고정 분할 방식을 예시로 살펴보자. 크기가 5MB인 프로세스 A가 있고, 2MB인 프로세스 B와 1MB인 프로세스 C가 있다고 가정해보자.
가변 분할 방식은 프로세스의 크기에 따라 메모리를 나누기 때문에 메모리에 프로세스 A를 위한 5MB를 확보하고, 프로세스 B를 위한 2MB를 확보하고, 프로세스 C를 위한 1MB를 확보한다. 한 프로세스가 메모리의 연속된 공간에 할당되기 때문에 연속 메모리 할당이라고 한다.
고정 분할 방식은 프로세스의 크기에 상관없이 메모리를 정해진 크기로 나눈다. 여기서 메모리 크기를 2MB로 나눈다고 가정하자. 그러면 5MB가 필요한 프로세스 A는 2MB로 나눈 구역 3개에 나눠서 할당된다. 1MB는 빈 공간으로 남는다. 프로세스 B는 2MB이기 때문에 크기가 정확히 맞는다. 프로세스 C는 1MB이지만 메모리에 2MB를 할당하고 1MB는 빈 공간으로 남는다. 이 방식은 한 프로세스가 메모리에 분산되어 할당되기 때문에 비연속 메모리 할당이라고 한다.
그러면 가변 분할 방식과 고정 분할 방식의 장단점을 알아보자.
가변 분할 방식
- 장점은 메모리의 연속된 공간에 할당되기 때문에 더 크게 할당되서 낭비되는 공간인 내부 단편화가 없다.
- 단점으로는 외부 단편화가 발생한다.
고정 분할 방식
- 장점으로는 구현이 간단하고 오버헤드가 적다.
- 적은 프로세스도 큰 영역에 할당되어 공간이 낭비되는 내부 단편화가 발생한다.
가변 분할 방식에서 발생하는 외부 단편화 문제를 알아보자. 가상 메모리 시스템에서는 가변 분할 방식을 세그멘테이션이라고 부른다.
메모리에 서로 다른 크기를 가지고 있는 여러 개의 프로세스가 올라왔다가 가정해보자. 처음 이 상황에서는 문제가 없다. 프로세스 A와 프로세스 D가 작업을 마치고 메모리에서 내려간다. 여기서 메모리에 프로세스 A와 프로세스 D가 있던 공간에 빈 공간이 생긴다. 프로세스 A가 있던 공간은 50MB, 프로세스 D가 있던 공간은 10MB이다. 여기서 크기가 60MB인 프로세스가 메모리를 원한다고 해보자. 프로세스 A와 프로세스 D의 공간을 합치면 60MB이니 할당을 할 수 있을 것 같지만 연속된 공간이 아니기 때문에 새로운 프로세스에게 메모리를 할당할 수 없다. 이것을 외부 단편화라고 부른다.
이런 상황이 발생했을 때 어떻게 하면 좋을까? 외부 단편화가 발생한 공간을 합쳐주는 조각 모음을 하면 된다. 하지만 조각 모음을 하면 현재 메모리에서 실행되고 있는 프로세스들의 작업을 일시 중지해야 하고 메모리 공간을 이동시키는 작업을 해야하기 때문에 오버헤드가 발생하게 된다.
고정 분할 방식에서 발생하는 내부 단편화 문제를 알아보자. 가상 메모리 시스템에서는 고정 분할 방식을 페이징이라고 부른다. 책의 페이지처럼 크기가 정해져 있다고 해서 붙은 이름이다.
메모리에 서로 다른 크기를 가지고 있는 여러 개의 프로세스가 올라왔다고 가정해보자. 이 예시에서는 20MB로 크기로 메모리를 분할한다고 가정하자. 각가의 프로세스들이 필요한 공간만큼 20MB로 쪼개져 할당된다. 메모리가 부족하기 때문에 프로세스 A의 나머지 10MB는 스왑 영역에 할당된다. 여기서 프로세스 C와 프로세스 D의 크기는 분할된 크기보다 작기 때문에 내부에 빈 공간이 생겨서 낭비된다. 이를 내부 단편화라고 부르는데, 이를 해결할 방법은 없고 분할되는 크기를 조절해서 내부 단편화를 최소화한다.
오늘날의 운영체제는 가변 분할 방식과 고정 분할 방식을 혼합하여 단점을 줄였다. 그러면 가변 분할 방식과 고정 분할 방식을 혼합해 단점을 최소화한 버디 시스템에 대해 알아보자. 버디 시스템은 e의 승수로 메모리를 분할해 메모리를 할당하는 방식이다.
계산의 편의성을 위해서 작은 값으로 알아보자. 메모리 크기가 2^11인 2048Byte라고 가정하자. 크기가 500Byte인 프로세스가 메모리 할당을 원한다. 그럼 먼저 e의 승수로 500Byte보다 작은 값을 만날 때까지 나눈다. 세 번을 나누면 256Byte 공간이 나오는데, 여기엔 500Byte 프로세스를 할당할 수 없다. 그럼 이보다 더 큰 구역인 512Byte 공간의 프로세스를 할당한다. 여기서도 내부 단편화가 발생하지만 12byte 밖에 발생하지 않는다.
이 프로세스가 사용을 마치고 메모리에서 나가도 근접한 메모리 공간을 합치기 쉽다. 그 이유는 e의 승수로 나눠서 반대로 조립만 하면 큰 공간이 만들어지기 때문에 조각 모음보다 훨씬 간단하다.
이 방식의 장점은 가변 분할 방식처럼 프로세스 크기에 따라 할당되는 메모리 크기가 달라지고, 외부 단편화를 방지하기 위해 메모리 공간을 확보하는 것이 간단하다. 또한 고정 분할 방식처럼 내부 단편화가 발생하기는 하지만 많은 공간의 낭비가 발생하지는 않는다.
참고
댓글남기기